
一、RAGFlow 简介
RAGFlow 是一个开源的检索增强生成(RAG, Retrieval-Augmented Generation)框架,提供了灵活的组件化架构来构建高效的 RAG 系统。本文记录了我学习 RAGFlow 框架的要点与实践体会。
RAGFlow 由阿里巴巴开源,旨在简化 RAG 系统的开发流程。它支持数据预处理、向量化、检索、生成等全流程,适合快速搭建问答、知识库等 AI 应用。
二、架构与核心组件
1 | ┌────────────┐ ┌────────────┐ ┌────────────┐ |
Processor:数据清洗、分割
Embedder:文本/多模态向量化
Retriever:向量检索
Generator:大模型生成
三、典型流程
数据预处理(分割、清洗)
文本/多模态向量化
向量入库
检索相关内容
结合检索结果生成答案
四、RAGFlow 框架使用
Python API 示例
初始化 RAG Flow
1 | rag_object = RAGFlow(api_key="YOUR_API_KEY", base_url="YOUR_BASE_URL") |
其中源代码为:
1 | def __init__(self, api_key, base_url, version="v1"): |
上述代码解释:
api_key:用户 API 密钥,用于身份验证。base_url:RAG Flow 服务器的 URL。version:API 版本,默认为v1。
上述代码主要完成的工作是: 初始化 RAG Flow 客户端。后期的所有操作,我们都是通过对创建好的 RAG Flow 对象,调用对应的 self(相当于 Java 中的 this)成员方法来操作的,比如:
create_dataset:创建数据集。list_datasets:列出数据集。delete_dataset:删除数据集。create_chat:创建会话。
等等。
知识库(dataset)管理相关API
创建不同粒度的数据集
注意,这里需要说明的是,对于 RAG Flow 的前端页面上,我们可以看到有 Knowledge Base,利用前端创建知识库时,会显示配置知识库,此时就需要填写一些内容,而这些内容,刚好对应于代码中的「数据集 dateset」所以,个人认为,可以将代码中的 dataset 理解为知识库。
知识库就是数据集。
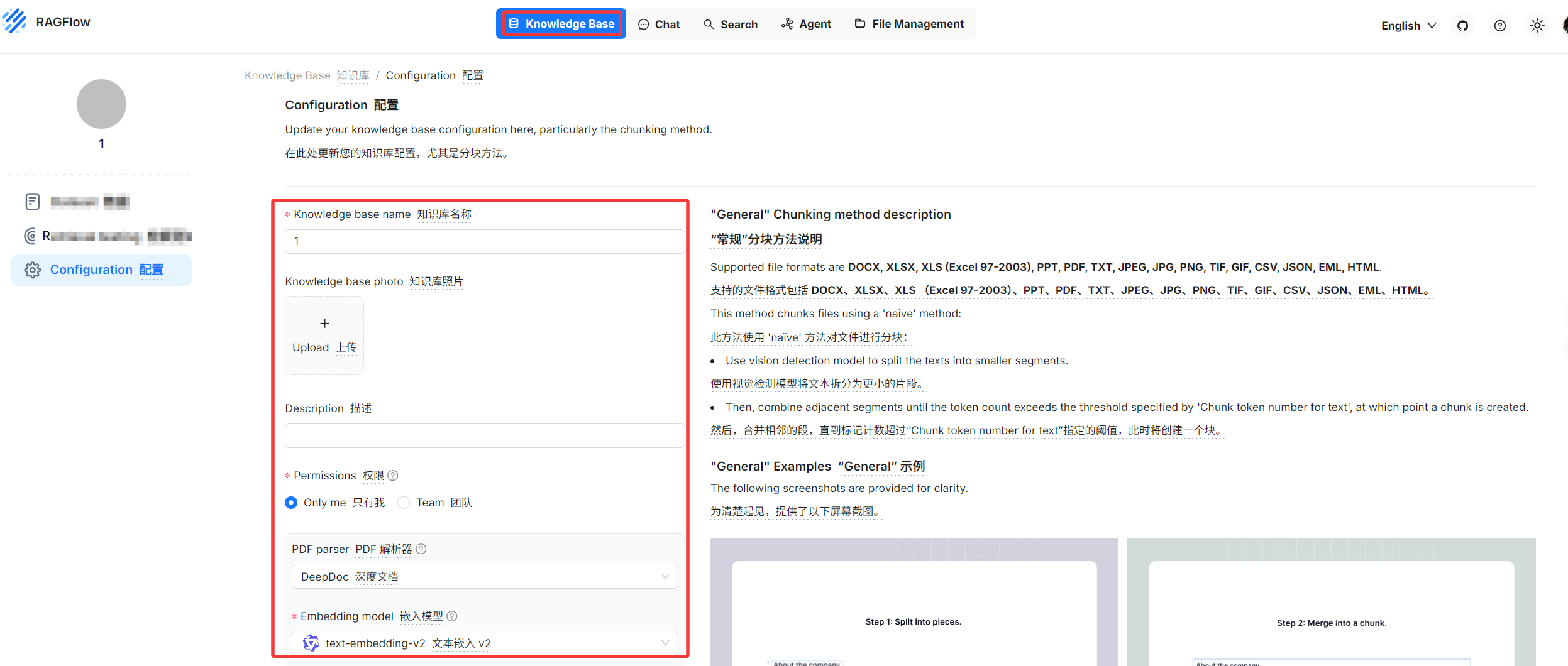
因此,下方代码中的创建数据集,就是页面上的创建知识库。
1 | def create_dataset( |
创建不同分块方法的数据集
1 | def create_dataset_example(self): |
上述方法,会创建 11 个数据集,分别使用不同的分块方法,这些分块方法用于常见的文档类型,比如:
以下是 RAGFlow 框架中的 chunk_methods 的分类及每种分块方法的简单介绍,结合其适用场景和特点:
naive(通用分块)
特点:
- 默认分块方法,适合处理常规文本。
- 使用自然分隔符(如换行符、标点符号)切分,同时控制块大小(通常不超过指定的 Token 数)。
适用场景:
- 通用文档,如政策文件、产品说明等格式较规范的文本。
优点:
- 简单高效,无需复杂配置。
manual(手动分块)
特点:
- 仅支持 PDF 格式,假设文档具有分层结构(如章节标题)。
- 使用最低级别的标题作为切片基准,保留章节内的图表和表格完整性,块大小可能较大。
适用场景:
- 手册类文档,如设备手册、技术规范等。
优点:
- 保留章节内容完整性,适合逻辑紧密的文档。
qa(问答格式分块)
特点:
- 专用于问答对格式的文档。
- 如果是 Excel 文件,需两列分别存储问题和答案;如果是 CSV/TXT 文件,以 TAB 分隔问题和答案。
适用场景:
- 问答对形式的知识库,例如常见问题解答(FAQ)。
优点:
- 适合问答场景,检索精准。
table(表格分块)
特点:
- 专用于表格数据,将表中每一行作为一个块。
- 支持 CSV、TXT 和 Excel 文件,列标题必须有意义。
适用场景:
- 表格数据,如统计报表、数据库导出文件。
优点:
- 保留表格结构,支持行列检索。
paper(论文分块)
特点:
- 专用于学术论文,按论文章节(如摘要、引言、方法等)切分。
- 增强论文的结构化检索能力。
适用场景:
- PDF 格式的学术论文。
优点:
- 提高论文检索和引用精度,但计算成本较高。
book(书籍分块)
特点:
- 专用于书籍文档,支持按章节或页面范围切分。
- 块大小可调整,适合长文档。
适用场景:
- 书籍或长篇文档,如小说、技术书籍。
优点:
- 保留书籍逻辑结构,适合全文检索。
laws(法律分块)
特点:
- 专用于法律文件,利用文本特征(如条款号)切分。
- 块粒度通常与条款一致,包含相关上下文。
适用场景:
- 合同、法律法规文件。
优点:
- 检索精准,适配法律文件的严格格式。
presentation(演示文稿分块)
特点:
- 专用于 PPT 或 PDF 格式的演示文稿。
- 每页幻灯片作为一个块,同时存储缩略图。
适用场景:
- 幻灯片文件,如报告、演示材料。
优点:
- 保留幻灯片结构,支持视觉化检索。
picture(图片分块)
特点:
- 专用于图片文档,支持 OCR(文字识别)和布局分析。
- 图片中的文字和标题被识别后作为块处理。
适用场景:
- 图片或扫描件。
优点:
- 可处理非结构化图片文档,支持图文检索。
one(单一文档块)
特点:
- 将整个文档作为一个块处理,不进行分割。
适用场景:
- 短文档或需要全文检索的场景。
优点:
- 保留文档完整性,适合全文检索。
email(电子邮件分块)
特点:
- 专用于邮件文件,解析邮件内容并按邮件主题或段落切分。
适用场景:
- 电子邮件或邮件存档。
优点:
- 提取邮件关键信息,便于邮件检索。
列出数据集
1 | def list_datasets(self, page: int = 1, page_size: int = 30, orderby: str = "create_time", desc: bool = True, id: str | None = None, name: str | None = None) -> list[DataSet]: |
上述方法用于列出数据集,并返回一个包含所有数据集的列表。
其可选的查询参数说明如下:
page: 页码,默认为1
page_size: 每页数量,默认30
orderby: 排序字段,默认为create_time
desc: 是否倒序,默认True
id: 数据集ID 注意,这里存在一个权限问题,对于填了 me 权限的,团队的其他用户是无法搜索到的,哪怕ID正确。
name: 数据集名称
查询所有数据集
1
2
3
4
5
6
7# 1. 列出所有数据集
all_datasets = self.rag_object.list_datasets()
print(f"总共有{len(all_datasets)} 个数据集:")
for dataset in all_datasets:
print(
f" - {dataset.name} (ID: {dataset.id}, 创建时间: {getattr(dataset, 'create_time', 'N/A')})"
)指定页编码以及页数,分页查询数据集
1
2
3
4
5# 2. 分页列出数据集
page_datasets = self.rag_object.list_datasets(page=1, page_size=5)
print(f"\n第一页数据集 (每页5个):")
for dataset in page_datasets:
print(f" - {dataset.name}")按更新时间排序查询数据集
1
2
3
4
5
6
7
8time_sorted_datasets = self.rag_object.list_datasets(
orderby="update_time", desc=True
)
print("\n按更新时间排序的数据集:")
for dataset in time_sorted_datasets[:3]: # 只显示前3个
print(
f" - {dataset.name} (更新时间: {getattr(dataset, 'update_time', 'N/A')})"
)遍历所有数据集,检查权限
1
2
3
4
5
6
7
8
9
10
11
12
13# 4. 遍历所有数据集,分别输出有权限和无权限的数据集
print("\n=== 遍历所有数据集,检查权限 ===")
has_permission = []
no_permission = []
for dataset in all_datasets:
try:
# 尝试用ID查找,能查到说明有权限
self.rag_object.list_datasets(id=dataset.id)
has_permission.append(dataset.name)
except Exception as e:
no_permission.append(dataset.name)
print(f"\n当前用户有权限的数据集: {has_permission}")
print(f"当前用户无权限的数据集: {no_permission}")
更新数据集
1 | def update_dataset_example(self, dataset_id: str): |
删除数据集
完整代码
1 | class DatasetManager: |